-
튜토리얼 정독 - (Cascade Classifier)Python/Python OpenCV 2020. 5. 6. 15:06반응형
음 필자도 아직 학생이다 보니까 너무 어려운기술도 많고 아직은 낯선기술도 너무 많다
또 혼자 예제를 실행하고 슥 넘어가면 다소 잊어버리기도하고 모르는 부분도 이해 못하고 넘어가기도하는데
그걸 방지하고자 쓴 글입니다.
먼저 OpenCv 공식사이트에서 몇가지 튜토리얼들을 제공해주는데 그 중에서 요즘 하고 있는 프로젝트에 도움이 될 수 있는 Cascade Classifier 를 진행할 예정입니다.
Cascade Classifier
Goal
In this tutorial,
- We will learn how the Haar cascade object detection works.
- We will see the basics of face detection and eye detection using the Haar Feature-based Cascade Classifiers
- We will use the cv::CascadeClassifier class to detect objects in a video stream. Particularly, we will use the functions:
- cv::CascadeClassifier::load to load a .xml classifier file. It can be either a Haar or a LBP classifier
- cv::CascadeClassifier::detectMultiScale to perform the detection.
첫째 구체적인 목표는 케스케이드에 객체 감지 방법을 공부하고
둘째 Haar Feature-based Cascade Classifiers를 사용하여 얼굴 감지 및 눈 감지를 한다고한다 .
셋째 cv :: CascadeClassifier 클래스를 사용하여 비디오 스트림에서 객체를 감지 상세 기능은 3-1,3-2
3-1 cv::CascadeClassifier::load는 xml분류기 파일을 업로드한다고 하네요 Haar 또는 LBP 분류기 일수 있 다고합니다
3-2 cv :: CascadeClassifier :: detectMultiScale 을 사용하여 탐지를 수행
Theory
Object Detection using Haar feature-based cascade classifiers is an effective object detection method proposed by Paul Viola and Michael Jones in their paper, "Rapid Object Detection using a Boosted Cascade of Simple Features" in 2001. It is a machine learning based approach where a cascade function is trained from a lot of positive and negative images. It is then used to detect objects in other images.
대충 Haar 기반 캐스케이드 분류기 에 대한 설명으로 효과적인 객체 탐지 방법입니다. 캐스케이드 기능은 많은 긍정적(얼굴이 인식된 이미지 ) 와 부정적인( 얼굴이 없는 이미지 ) 이미지에서 훈련됩니다. 그런 다음 다른 이미지에서 물체를 감지하는 데 사용됩니다.
Here we will work with face detection. Initially, the algorithm needs a lot of positive images (images of faces) and negative images (images without faces) to train the classifier. Then we need to extract features from it. For this, Haar features shown in the below image are used. They are just like our convolutional kernel. Each feature is a single value obtained by subtracting sum of pixels under the white rectangle from sum of pixels under the black rectangle.
알고리즘 분류기를 훈련시킬려면 긍정적 이미지와 부정적 이미지 가 많이 필요하다 . 이를 위해 아래 이미지에 표시된 Haar 기능이 사용된다고 합니다. 각 피처는 검은 색 사각형 아래의 픽셀 합계에서 흰색 사각형 아래의 픽셀 합계를 빼서 얻은 단일 값입니다 (이때 convolutional kernel 이러한 기법과 유사하다고 하네요 )
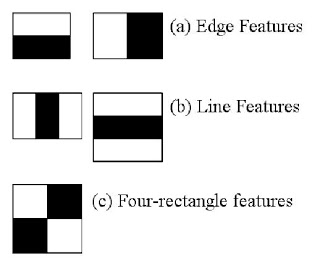
image
Now, all possible sizes and locations of each kernel are used to calculate lots of features. (Just imagine how much computation it needs? Even a 24x24 window results over 160000 features). For each feature calculation, we need to find the sum of the pixels under white and black rectangles. To solve this, they introduced the integral image. However large your image, it reduces the calculations for a given pixel to an operation involving just four pixels. Nice, isn't it? It makes things super-fast.
대충 이미지를 계산하는데 많은 자원이 필요하다고 하고 이를 해결하기 위해 integral image를 도입했다고 하네요
But among all these features we calculated, most of them are irrelevant. For example, consider the image below. The top row shows two good features. The first feature selected seems to focus on the property that the region of the eyes is often darker than the region of the nose and cheeks. The second feature selected relies on the property that the eyes are darker than the bridge of the nose. But the same windows applied to cheeks or any other place is irrelevant. So how do we select the best features out of 160000+ features? It is achieved by Adaboost.
그러나 우리가 계산한 모든 값 들은 기능과 대부분 관련이 없다네요 (아래 이미지를 참조)맨 윗줄에는 두 가지 좋은 기능이 있습니다. 선택된 첫 번째 특징은 눈의 영역이 종종 코와 뺨의 영역보다 어둡다는 특성에 초점을 맞추는 것 같습니다. 두 번째 특징은 눈이 코의 다리보다 어둡다는 속성에 의존합니다
그러나 이러한 것들도 단점이없는건 아니다 . 뺨이나 다른 장소에 적용되는 매커니즘이 없다 그렇다면 우리는 162336개 특성중에서 무엇이 최고 인지는 어떻게 찾는지 궁금하다 그것은 바로 Adaboost 라는 것을 통해 해결한다.

image
For this, we apply each and every feature on all the training images. For each feature, it finds the best threshold which will classify the faces to positive and negative. Obviously, there will be errors or misclassifications. We select the features with minimum error rate, which means they are the features that most accurately classify the face and non-face images. (The process is not as simple as this. Each image is given an equal weight in the beginning. After each classification, weights of misclassified images are increased. Then the same process is done. New error rates are calculated. Also new weights. The process is continued until the required accuracy or error rate is achieved or the required number of features are found).
이를 위해 모든 교육 이미지에 각각의 모든 기능을 적용합니다. 각 기능에 대해면을 양수와 음수로 분류 할 최상의 임계 값을 찾습니다. 분명히 오류나 오 분류가있을 것입니다. 최소 오류율을 가진 기능을 선택합니다. 즉, 얼굴 및 비면 이미지를 가장 정확하게 분류하는 기능입니다(처음에는 각 이미지에 동일한 가중치가 부여됩니다. 각 분류 후에 잘못 분류 된 이미지의 가중치가 증가합니다. 그런 다음 동일한 프로세스가 수행됩니다. 새로운 오류율이 계산됩니다. 또한 새로운 가중치가 있습니다. 필요한 정확도 또는 오류율에 도달하거나 필요한 수의 기능을 찾을 때까지 프로세스가 계속됩니다)
The final classifier is a weighted sum of these weak classifiers. It is called weak because it alone can't classify the image, but together with others forms a strong classifier. The paper says even 200 features provide detection with 95% accuracy. Their final setup had around 6000 features. (Imagine a reduction from 160000+ features to 6000 features. That is a big gain).
최종 분류기는 이러한 약한 분류기의 가중치 합계입니다. 단독으로는 이미지를 분류 할 수 없기 때문에 약한 것으로 불리지 만 다른 것들과 함께 강력한 분류기를 형성합니다. 이 논문은 200 개의 기능조차도 95 %의 정확도로 탐지를 제공한다고 말합니다.
So now you take an image. Take each 24x24 window. Apply 6000 features to it. Check if it is face or not. Wow.. Isn't it a little inefficient and time consuming? Yes, it is. The authors have a good solution for that.
이제 이미지를 찍습니다. 각 24x24 창을 가져 가십시오. 그것에 6000 기능을 적용하십시오. 얼굴인지 확인하십시오. 와우 .. 비효율적이고 시간이 많이 걸리지 않습니까? 그렇습니다. 저자는 그에 대한 좋은 해결책을 가지고 있습니다.
In an image, most of the image is non-face region. So it is a better idea to have a simple method to check if a window is not a face region. If it is not, discard it in a single shot, and don't process it again. Instead, focus on regions where there can be a face. This way, we spend more time checking possible face regions.
이미지에서 이미지의 대부분은 비면 영역입니다. 따라서 창이면 영역이 아닌지 확인하는 간단한 방법을 사용하는 것이 좋습니다. 그렇지 않은 경우 한 번에 버리고 다시 처리하지 마십시오. 대신 얼굴이있을 수있는 영역에 초점을 맞추십시오. 이런 식으로, 가능한 얼굴 영역을 확인하는 데 더 많은 시간을 소비합니다.
For this they introduced the concept of Cascade of Classifiers. Instead of applying all 6000 features on a window, the features are grouped into different stages of classifiers and applied one-by-one. (Normally the first few stages will contain very many fewer features). If a window fails the first stage, discard it. We don't consider the remaining features on it. If it passes, apply the second stage of features and continue the process. The window which passes all stages is a face region. How is that plan!
이를 위해 그들은 Cascade of Classifiers 라는 개념을 도입했습니다 . 6000 개의 모든 피처를 창에 적용하는 대신 피처는 여러 분류기 단계로 그룹화되어 하나씩 적용됩니다
반적으로 처음 몇 단계에는 훨씬 적은 수의 기능이 포함됩니다. 창이 첫 번째 단계에 실패하면 버립니다. 나머지 기능은 고려하지 않습니다. 통과하면 기능의 두 번째 단계를 적용하고 프로세스를 계속하십시오. 모든 단계를 통과하는 창은 얼굴 영역입니다.
The authors' detector had 6000+ features with 38 stages with 1, 10, 25, 25 and 50 features in the first five stages. (The two features in the above image are actually obtained as the best two features from Adaboost). According to the authors, on average 10 features out of 6000+ are evaluated per sub-window.
So this is a simple intuitive explanation of how Viola-Jones face detection works. Read the paper for more details or check out the references in the Additional Resources section.
Haar-cascade Detection in OpenCV
OpenCV provides a training method (see Cascade Classifier Training) or pretrained models, that can be read using the cv::CascadeClassifier::load method. The pretrained models are located in the data folder in the OpenCV installation or can be found here.
간단하게 훈련된 데이터는 위 링크에서 받을수 있고
The following code example will use pretrained Haar cascade models to detect faces and eyes in an image. First, a cv::CascadeClassifier is created and the necessary XML file is loaded using the cv::CascadeClassifier::load method. Afterwards, the detection is done using the cv::CascadeClassifier::detectMultiScale method, which returns boundary rectangles for the detected faces or eyes.
This tutorial code's is shown lines below. You can also download it from here
튜토리얼 코드는 위 링크에서 다운 받을 수 있다고 하네요 .
opencv/opencv
Open Source Computer Vision Library. Contribute to opencv/opencv development by creating an account on GitHub.
github.com
일단 준비물 cv2 와 https://github.com/opencv/opencv/tree/master/data/haarcascades에 들어가서
haarcascade_frontalface_alt.xml , haarcascade_eye_tree_eyeglasses.xml 을 받아옵니다from __future__ import print_function import cv2 as cv import argparse # 화면탐지 함수 def detectAndDisplay(frame): # 그레이 이미지를 띄움 (컬러보다 효율이 좋음) frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY) # 히스토그램 균일화 frame_gray = cv.equalizeHist(frame_gray) # detectMultiScale 함수는 얼굴을 검출하며 인자값으로 (그레이 스케일 이미지를) 받는다 # 얼굴이 검출되면 해당 위치를 리턴합니다 x , y w h faces = face_cascade.detectMultiScale(frame_gray) for (x, y, w, h) in faces: # 검출된 부분을 타원으로 그려줌 center = (x + w//2, y + h//2) frame = cv.ellipse(frame, center, (w//2, h//2), 0, 0, 360, (255, 0, 255), 4) # 회색 얼굴일때는 이런식으로 값을 계산해준다고합니다 faceROI = frame_gray[y:y+h, x:x+w] # 눈은 항상 얼굴 안에 있기에 그 안에서 검출해준다. eyes = eyes_cascade.detectMultiScale(faceROI) for (x2, y2, w2, h2) in eyes: # 눈위에 원을 그려준다 그아래는 원의 크기를 정의함 eye_center = (x + x2 + w2//2, y + y2 + h2//2) radius = int(round((w2 + h2)*0.25)) frame = cv.circle(frame, eye_center, radius, (255, 0, 0), 4) # 얼굴 감지 ! cv.imshow('Capture - Face detection', frame) #다음 코드는 정수 목록을 받아 합계 또는 최댓값을 출력하는 파이썬 프로그램입니다: #argparse 를 사용하는 첫 번째 단계는 ArgumentParser 객체를 생성하는것 . parser = argparse.ArgumentParser( description='Code for Cascade Classifier tutorial.') #parser에 add_argument 를 사용하여 학습된 xml 파일을 전송시켜줌 parser.add_argument('--face_cascade', help='Path to face cascade.', default='./haarcascade_frontalface_alt.xml') parser.add_argument('--eyes_cascade', help='Path to eyes cascade.', default='./haarcascade_eye_tree_eyeglasses.xml') #카메라 번호를 추가해줌 (카메라가 한대이면 0 ) parser.add_argument( '--camera', help='Camera divide number.', type=int, default=0) args = parser.parse_args() #face_cascade_name face_cascade_name = args.face_cascade eyes_cascade_name = args.eyes_cascade #cv에 있는 CascadeClassifier를 사용 face_cascade = cv.CascadeClassifier() eyes_cascade = cv.CascadeClassifier() # -- 1. cascades 를 불러옴 (미리 준비된학습데이터와 함께 ) if not face_cascade.load(cv.samples.findFile(face_cascade_name)): print('--(!)Error loading face cascade') exit(0) if not eyes_cascade.load(cv.samples.findFile(eyes_cascade_name)): print('--(!)Error loading eyes cascade') exit(0) camera_device = args.camera # -- 2. 비디오 객체를 불러옴 cap = cv.VideoCapture(camera_device) if not cap.isOpened: print('--(!)Error opening video capture') exit(0) while True: #카메라를 읽어옴 ret, frame = cap.read() if frame is None: print('--(!) No captured frame -- Break!') break #얼굴인식 시작 . detectAndDisplay(frame) #esc 키를 누르면 종료 if cv.waitKey(10) == 27: break위의 코드를 실행한 결과는 다음과 같습니다.
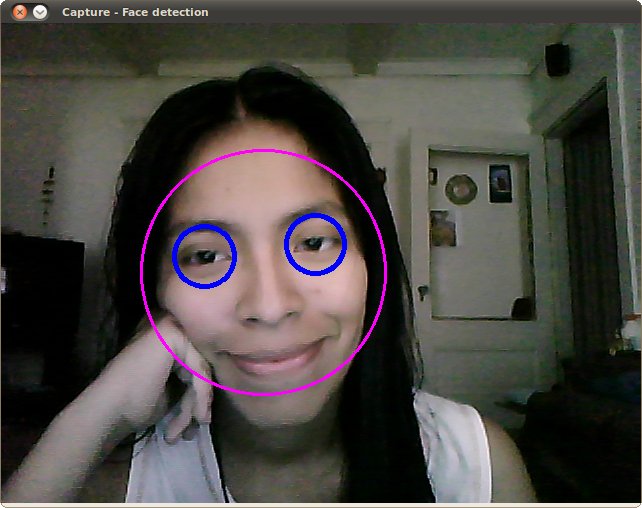 반응형
반응형'Python > Python OpenCV' 카테고리의 다른 글
이미지 처리(Image Processing)란? (0) 2024.08.02 끄적 끄적 (0) 2024.07.05 Python OpenCV (1. 사진 읽어오기 nameWindow, imshow , waitkey) (0) 2020.03.15